

티스토리 뷰
반응형

GDP이란?
GDP(국내총생산)은 한 나라의 경제 규모와 성장률을 보여주는 핵심 지표입니다.
이 문서에서는 실제 경제지, 국가기관, 연구소, 금융기관 등에서 사용하는 모든 주요 예측 방법론과, 각 방법의 해석·한계·실제적 맥락까지 빠짐없이 정리합니다.
이 문서에서는 실제 경제지, 국가기관, 연구소, 금융기관 등에서 사용하는 모든 주요 예측 방법론과, 각 방법의 해석·한계·실제적 맥락까지 빠짐없이 정리합니다.
1. 계량경제학적 모형(통계적 모델)
과거의 GDP와 소비, 투자, 수출입, 고용, 물가 등 다양한 경제지표 간의 통계적 관계를 분석해 미래의 GDP를 예측합니다.
대표적으로 선형회귀분석, VAR(벡터 자기회귀), ARIMA(시계열 분석) 등이 있습니다.
GDPt = α + β₁×소비t + β₂×투자t + β₃×수출t + εt
파이썬 예시 코드 (가상 데이터):
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import seaborn as sns
# 가상의 데이터 생성 (2010-2023년, 분기별 데이터)
np.random.seed(42)
periods = 56 # 14년 * 4분기
# 기본 추세와 계절성을 가진 데이터 생성
time = np.arange(periods)
consumption = 1000 + 5 * time + np.random.normal(0, 50, periods) + 50 * np.sin(time/4)
investment = 800 + 3 * time + np.random.normal(0, 40, periods) + 30 * np.sin(time/4)
exports = 1200 + 4 * time + np.random.normal(0, 60, periods) + 40 * np.sin(time/4)
# GDP 생성 (소비 + 투자 + 수출의 영향을 받되, 약간의 노이즈 추가)
GDP = 0.5 * consumption + 0.3 * investment + 0.2 * exports + np.random.normal(0, 30, periods)
# 데이터프레임 생성
data = pd.DataFrame({
'GDP': GDP,
'Consumption': consumption,
'Investment': investment,
'Exports': exports,
'Year': 2010 + time // 4,
'Quarter': time % 4 + 1
})
# 데이터 분할 (학습용 80%, 테스트용 20%)
X = data[['Consumption', 'Investment', 'Exports']]
y = data['GDP']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 선형회귀 모델 학습
model = LinearRegression()
model.fit(X_train, y_train)
# 모델 계수 출력
print("=== 모델 계수 ===")
print(f"절편 (α): {model.intercept_:.2f}")
print(f"소비 계수 (β1): {model.coef_[0]:.2f}")
print(f"투자 계수 (β2): {model.coef_[1]:.2f}")
print(f"수출 계수 (β3): {model.coef_[2]:.2f}")
# R-squared 값 계산
r2_train = model.score(X_train, y_train)
r2_test = model.score(X_test, y_test)
print(f"\nR-squared (학습 데이터): {r2_train:.4f}")
print(f"R-squared (테스트 데이터): {r2_test:.4f}")
# 실제값과 예측값 비교 그래프
plt.figure(figsize=(12, 6))
y_pred = model.predict(X)
plt.plot(data.index, y, label='실제 GDP', alpha=0.7)
plt.plot(data.index, y_pred, label='예측 GDP', alpha=0.7)
plt.title('GDP: 실제값 vs 예측값')
plt.xlabel('시간')
plt.ylabel('GDP')
plt.legend()
plt.grid(True)
plt.show()
# 상관관계 히트맵
plt.figure(figsize=(8, 6))
correlation_matrix = data[['GDP', 'Consumption', 'Investment', 'Exports']].corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', vmin=-1, vmax=1)
plt.title('경제지표 간 상관관계')
plt.show()
=== 모델 계수 ===
절편 (α): 15.58
소비 계수 (β1): 0.48
투자 계수 (β2): 0.40
수출 계수 (β3): 0.14
R-squared (학습 데이터): 0.8244
R-squared (테스트 데이터): 0.9362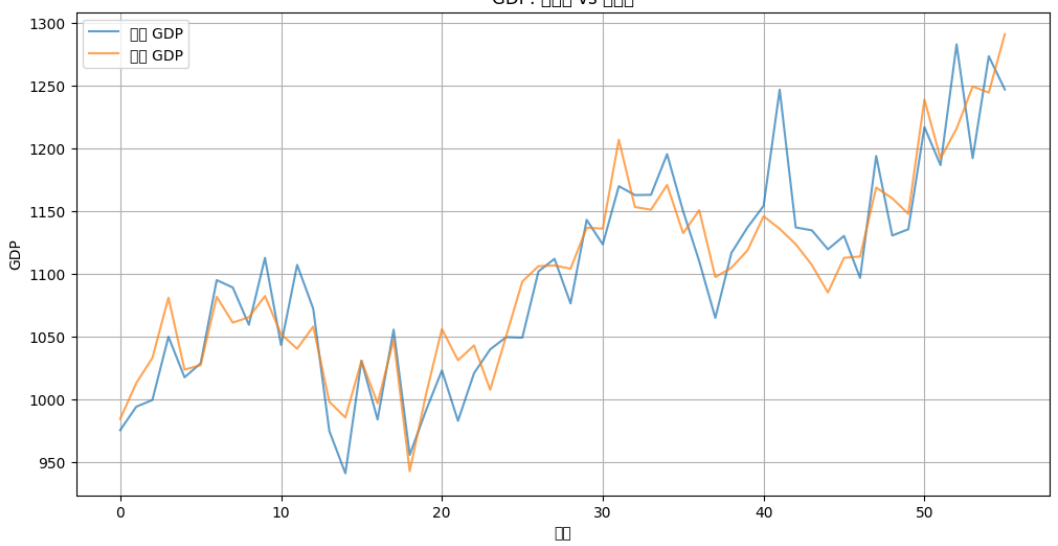
- 절편 (α): 15.58
- 소비 계수 (β1): 0.48
- 투자 계수 (β2): 0.40
- 수출 계수 (β3): 0.14
- R²(학습): 0.8244, R²(테스트): 0.9362
- 소비가 1단위 증가하면 GDP는 0.48단위 증가
- 투자가 1단위 증가하면 GDP는 0.40단위 증가
- 수출이 1단위 증가하면 GDP는 0.14단위 증가
- 소비가 GDP에 가장 큰 영향, 내수(소비+투자)가 주요 동인
- R²가 높아 설명력이 우수
장점
- 직관적, 해석 쉬움
- 구현 간단, 단기 예측에 효과적
한계
- 선형관계 가정(현실 단순화)
- 시차효과, 외부충격, 지하경제 등 반영 어려움
- 변수 간 상호작용 설명 부족
지하경제와 공식 통계의 한계
공식 GDP 예측 모델은 정부에서 집계한 공식 통계(세금 신고, 기업 보고, 무역 통계 등)만을 사용합니다.
세금 신고 없는 현금 거래, 불법 거래 등 지하경제는 통계에 잘 잡히지 않습니다.
지하경제 추정법: 통화수요 접근법, 전력소비 접근법, 비정상적 통계 패턴, 설문조사, 국제기구 추정 등.
결론: 지하경제는 공식 GDP에 거의 반영되지 않으며, 예측이 매우 어렵고 간접 추정만 가능합니다.
세금 신고 없는 현금 거래, 불법 거래 등 지하경제는 통계에 잘 잡히지 않습니다.
지하경제 추정법: 통화수요 접근법, 전력소비 접근법, 비정상적 통계 패턴, 설문조사, 국제기구 추정 등.
결론: 지하경제는 공식 GDP에 거의 반영되지 않으며, 예측이 매우 어렵고 간접 추정만 가능합니다.
2. 구조적 모형(Structural Model, DSGE)
경제이론에 기반해 경제 전체의 구조를 수식으로 모델링합니다.
대표적으로 DSGE(동태적 확률 일반균형) 모형이 있으며, 중앙은행, 정부 연구기관 등에서 많이 사용합니다.
maxCt,Lt E₀ Σ βᵗ[log(Cₜ) - φ(Lₜ²/2)]
- 가계의 효용 극대화: maxCt,Lt E₀ Σ βᵗ[log(Cₜ) - φ(Lₜ²/2)]
- 기업의 생산함수: Yt = At · Ltα
- 자원제약식: Yt = Ct + It + Gt
- 정책반응함수(테일러 준칙): rt = ρrt-1 + (1-ρ)[φπ(πt - π*) + φy(Yt - Y*)] + εt
- Ct: 소비, Lt: 노동, β: 할인율, φ: 노동 불편함의 강도
- Yt: 산출(=GDP), At: 기술수준, α: 노동 생산성
- It: 투자, Gt: 정부지출, rt: 정책금리, πt: 인플레이션, Y*: 잠재 GDP
- log(Ct): 소비에서 얻는 효용(행복감), 한계효용 체감
- -φLt²/2: 노동의 불편함(노동이 많아질수록 불편함이 제곱으로 증가), φ는 민감도
- βt: 미래 효용의 현재가치(할인), 예: β=0.95면 2년 뒤 효용은 0.95²=0.9025배
- 1/2는 미분(최적화)시 수식이 깔끔해지도록 관례적으로 붙임
U = log(C_t) - φL_t²/2
∂U/∂C_t = 1/C_t
∂U/∂L_t = -φL_t
예산제약: C_t = w_t L_t
최적화: 1/C_t * w_t = φL_t
- 가계는 소비와 노동의 균형을 선택해 평생 효용을 극대화
- 소비의 한계효용 = 임금 × 노동의 한계불편함이 되는 지점이 최적
- 구조적 모형은 “GDP가 왜, 어떻게 변하는가”를 설명하는 인과관계 해석에 강점
- β, φ 등 파라미터는 GDP 예측의 직접적 입력값은 아니지만, 경제주체의 행동을 결정해 결과적으로 GDP에 영향
장점
- 경제이론 기반 인과관계 해석
- 정책 효과, 시나리오 분석에 강점
- 파라미터 변화가 경제에 미치는 영향 분석 가능
한계
- 모형이 복잡, 많은 가정 필요
- 현실의 모든 복잡성 반영 어려움
- 예측 정확도는 단순 통계모형보다 떨어질 수 있음
결론: 구조적 모형은 예측에도 쓰이지만, “왜?”에 대한 해석에 특히 강점이 있음.
단순 통계모형은 “미래 수치 예측”에, 구조적 모형은 “정책 효과·인과관계 해석”에 각각 강점.
단순 통계모형은 “미래 수치 예측”에, 구조적 모형은 “정책 효과·인과관계 해석”에 각각 강점.
3. 시계열 예측 모형
과거 GDP 데이터만을 이용해 미래를 예측하는 방법입니다.
ARIMA, SARIMA, Exponential Smoothing, Prophet 등 다양한 시계열 예측 기법이 있습니다.
외생변수(다른 경제지표)를 고려하지 않고, GDP 자체의 패턴(추세, 계절성 등)에 집중합니다.
4. 머신러닝/딥러닝 기반 예측
최근에는 머신러닝(랜덤포레스트, XGBoost 등)이나 딥러닝(LSTM, RNN 등) 기법을 활용해 GDP를 예측하기도 합니다.
수많은 경제지표, 금융시장 데이터, 뉴스, 소셜미디어 데이터까지 입력 변수로 활용할 수 있습니다.
변수 간의 비선형적 관계나 복잡한 패턴을 포착하는 데 강점이 있습니다.
5. 전문가 설문조사(Consensus Forecast)
여러 경제 전문가, 연구기관의 전망치를 모아 평균(컨센서스)을 내는 방식입니다.
다양한 예측 모형과 전문가의 직관, 최신 이슈를 반영할 수 있다는 장점이 있습니다.
장점
- 다양한 전문가 의견 반영
- 정성적 요소 고려 가능
- 최신 이슈 반영 용이
한계
- 주관적 편향 가능성
- 극단적 상황 예측 어려움
- 합의 도출에 시간 소요
6. 실제 GDP 예측 과정 예시
- 데이터 수집: 과거 GDP, 소비, 투자, 수출입, 고용, 물가, 금리, 환율 등 다양한 경제지표 수집
- 모형 선택: 예측 목적과 데이터 특성에 따라 적합한 모형(계량경제학, 시계열, 머신러닝 등) 선택
- 모형 추정 및 학습: 과거 데이터를 이용해 모형의 파라미터를 추정하거나 학습
- 예측 및 시나리오 분석: 미래의 경제지표(혹은 시나리오)를 입력해 GDP 예측
- 결과 해석 및 보정: 예측 결과를 전문가가 해석하고, 필요시 보정하거나 추가 정보 반영
7. 요약 및 결론
- GDP 예측에는 계량경제학, 구조적 모형(DSGE), 시계열, 머신러닝/딥러닝, 전문가 설문 등 다양한 방법이 활용됨
- 각 방법은 장단점과 해석의 깊이가 다름
- 구조적 모형은 “왜?”에 대한 해석에 특히 강점
- 지하경제 등 공식 통계에 잡히지 않는 부분은 예측이 어렵고, 간접 추정만 가능
- 실제 예측은 여러 방법을 조합해 사용하며, 전문가의 해석과 보정이 중요함
반응형
'자기개발 > 경제' 카테고리의 다른 글
| 플라잉 택시: 미래 교통의 혁신과 Vertical Aerospace 사례로 본 투자 인사이트 (3) | 2025.04.24 |
|---|---|
| 긱 이코노미, 일의 미래를 바꾸다: 플랫폼 노동의 명암과 Hotplate 사례로 본 투자 인사이트 (0) | 2025.04.23 |
| 통화정책과 경제 안정: 경제학에서 꼭 알아야 할 핵심 지식 (0) | 2025.04.19 |
| 통화정책의 균형술: 2025년 글로벌 경제 안정을 위한 중앙은행의 역할 (1) | 2025.04.18 |
| 2025년 4월 17일 뉴스 및 미국 경제 전망: 연준 정책, 월스트리트 수정, 그리고 구조적 회복력 (0) | 2025.04.17 |
반응형
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- 맛집
- 원주맛집
- 통화정책
- 레시피
- 금융시장
- LLM
- 글로벌경제
- 내돈내산
- 파이썬
- 인플레이션
- 알마티
- python
- 카자흐스탄
- 여행
- 캠핑
- 데이터센터
- 뉴스자동화
- 경제 상식
- 춘천여행
- 코딩
- 경제학 개념
- 투자전략
- 요리레시피
- 프랑스
- 닭요리
- 파이썬실용
- 야후뉴스
- 뉴스케일파워
- 원주
- 요리
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
글 보관함